
It’s been long – too long to be honest – since I’ve posted an updated about the SightPlayer project and I deeply apologize for it.
But there is light at the end of the tunnel: I’ve started my research at the TU Wien a few months ago, trying to figure out how to make SightPlayer real. But wait a second. Wasn’t the app almost done? Didn’t say the homepage: “Coming soon”? Yes it was and yes it did. But our team fell into the same pitfall, like many researchers and students in the past: We underestimated the difficulties of Optical Music Recognition. So I took a step back and revisited the algorithms and tools that we used to build SightPlayer and decided to take a completely new approach.
But what was wrong with it? It looked quite nice. What exactly are you trying to solve?
To sum it up: The goal is to take an image of music scores, let the computer or smartphone detect it and then play it back to you. Research in this direction has been conducted since 1966! When we launched SightPlayer, it was the first project that attempted to achieve this entirely on the Smartphone. There are two commercial applications that attempt the same thing and work similarly bad in the wild. In retrospective, its good we did not release it, or we would have gotten the same bad feedback, but would have spoiled the name.
When you are familiar with Computer Vision, then the problem statement and the approach seems kind of obvious: Detect the staff-lines, remove them, do some template matching to detect smaller symbols and finally restore the information that is required to play it back. But the bitter truth is: It is not that easy. There are many subtleties that make a huge difference when using the system on a real dataset. Take a look at these notes, and tell me how the templates should look like:
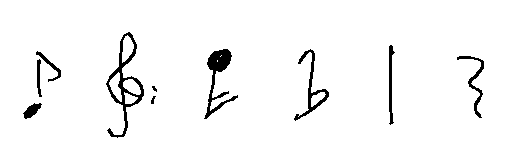
Well, these symbols look fairly normal, although they are handwritten. I guess by adding some templates, I will catch them. But what to do when they are put in context or look a little different?
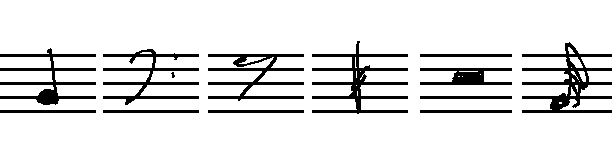
You will need a lot of templates. So, some researchers try to find the staff-lines and then remove them, which is the first step where I disagree with most researchers: Why discard information, that guides our reading and is required to make sense of the actual notes? I claim, that removing the staff-lines is not required, if the right approach is used.
But what is the right approach, though?
My hopes lie in a new technology, called Deep Learning. Check it out, if you have never hear about it before. Basically it’s a really clever way of doing machine learning, where you can perform supervised learning very easily – you more or less just provide the data and the expected output – and let the machine figure out the rest by itself. In practice, it’s a little bit more challenging, but you get the idea.
So far, I had great success with classifying handwritten music symbols and entire images of music scores. Check this out:

This handsome Android application can distinguish music scores from arbitrary content in real-time! And also the classifier for handwritten music symbols works quite well – actually it performs even better than humans. It only errs with symbols like these:

But to be honest, you need some fantasy to guess the right classes of music symbols here (they are Sixteenth-Rest, 2-4-Time, Sixteenth-Note, Cut-Time, Quarter-Rest and Sixteenth-Note).
The next step is to locate music symbols in an entire sheet of music scores. I hope that it will work out as well as the first few experiments.
From now on, I will keep you updated more regularly on my research progress. I promise!
