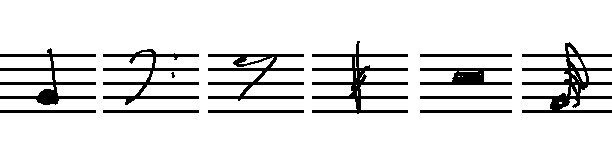This year’s edition of the Applied Deep Learning course at the TU Wien is again taking place online, so if you are interested in Deep Learning and you haven’t done so last year, you can watch all lectures in this playlist. New lecture videos will be added every week.
The official course description can be found in TISS.
This year’s edition of the Applied Deep Learning course at the TU Wien has moved to YouTube because of COVID-19. If you are interested in Deep Learning, you can watch all lectures in this playlist. New lecture videos will be added every week.
The official course description can be found in TISS.
I am very happy to announce that I’ve successfully completed my doctoral studies and defended my thesis on the 4th of July 2019. I’m now officially Dr. techn. Alexander Pacha.
For my defense, I prepared a 45-minutes presentation. Unfortunately, not everyone who might be interested in it was able to physically join the event, so I decided to re-record the presentation and uploaded the video to YouTube. I hope you enjoy watching it, as it summarized all of the work that I’ve been doing in the last two-and-a-half years in less than an hour:
Recently I was struggling with the fact that one of the datasets, that I was working with had the same images, but they were not correctly aligned. Since one of them had location annotations that I used for training a Music Object Detector, I had to align them somehow.
For getting an impression on the alignment-error, look at the following images:
Black-and-White Image
Unaligned Grayscale Image
Bitwise difference between the images
The top-left image is the binarized image which serves as a reference. The top-right image is the original gray-scale image that is misaligned a tiny little bit, which you can’t even notice from just looking at them. So I’ve generated the bit-wise difference between the two images which is shown at the bottom and there you can almost read the full scores because they are slightly shifted and misplaced.
Generating such a diff-image from two images in Python with the Pillow library basically boils down to:
allowing me to visually verify whether or not the images were aligned correctly.
Turns out, that almost every image in the dataset was transformed a little bit. Since the dataset contains 1000 images in multiple flavors, I needed some automation. As you can notice, the images are not very far apart from each other. So upon searching for a clever solution, I found a nice blog entry which attempts to align color channels of images, that are slightly misaligned, by applying an iterative algorithm to find an affine transformation (which is generally a very hard task). Luckily, that algorithm is readily implemented in OpenCV and is called cv2.findTransformECC. Using it is almost newbie-friendly:
from cv2 import cv2, countNonZero, cvtColor
im1 = cv2.imread(path_to_desired_image)
im2 = cv2.imread(path_to_image_to_warp)
warp_mode = cv2.MOTION_AFFINE
warp_matrix = np.eye(2, 3, dtype=np.float32)
# Specify the number of iterations.
number_of_iterations =100
# Specify the threshold of the increment in the correlation
# coefficient between two iterations
termination_eps =1e-7
criteria = (cv2.TERM_CRITERIA_EPS| cv2.TERM_CRITERIA_COUNT,
number_of_iterations, termination_eps)
# Run the ECC algorithm. The results are stored in warp_matrix.
(cc, warp_matrix) = cv2.findTransformECC(im1, im2, warp_matrix,
warp_mode, criteria)
Lastly, one “only” needs to warp the image with the found affine transformation:
# Get the target size from the desired image
target_shape = im1.shape
aligned_image = cv2.warpAffine(
unaligned_image,
warp_matrix,
(target_shape[1], target_shape[0]),
flags=cv2.INTER_LINEAR+ cv2.WARP_INVERSE_MAP,
borderMode=cv2.BORDER_CONSTANT,
borderValue=0)
cv2.imwrite(destination_path, aligned_image)
The final result is remarkable. Can you still see the difference?
Bitwise difference between the aligned images. A black pixel appears, where the images are not the same. Since the images are aligned, the image is almost completely white.
Just a few pixels remain, and these are because of errors during binarization of the image, which necessarily is a lossy operation. A cool side-effect is that the images are now not only aligned but also have the same size.
The only things, I needed to tweak a little bit where the two parameters number_of_iterations and termination_eps. Both are required for the cv2.findTransformECC algorithm and specify the maximum time that it tries to find a solution and the required quality before stopping. When either is satisfied, the algorithm stops and returns the found solution. Letting the algorithm run for a few hours, yielded a perfectly aligned the dataset, which allows me now to go back to train my networks to detect musical objects.
If you are interested in the full source-code, you can find it in this Github repository.
The score images depicted in this article are from the CVC-MUSCIMA dataset by Alicia Fornés, Anjan Dutta, Albert Gordo, and Josep Lladós, licensed under CC BY-NC-SA 4.0. More information on the dataset can also be found here as well as in their original paper.
It’s been long – too long to be honest – since I’ve posted an updated about the SightPlayer project and I deeply apologize for it.
But there is light at the end of the tunnel: I’ve started my research at the TU Wien a few months ago, trying to figure out how to make SightPlayer real. But wait a second. Wasn’t the app almost done? Didn’t say the homepage: “Coming soon”? Yes it was and yes it did. But our team fell into the same pitfall, like many researchers and students in the past: We underestimated the difficulties of Optical Music Recognition. So I took a step back and revisited the algorithms and tools that we used to build SightPlayer and decided to take a completely new approach.
But what was wrong with it? It looked quite nice. What exactly are you trying to solve?
To sum it up: The goal is to take an image of music scores, let the computer or smartphone detect it and then play it back to you. Research in this direction has been conducted since 1966! When we launched SightPlayer, it was the first project that attempted to achieve this entirely on the Smartphone. There are two commercial applications that attempt the same thing and work similarly bad in the wild. In retrospective, its good we did not release it, or we would have gotten the same bad feedback, but would have spoiled the name.
When you are familiar with Computer Vision, then the problem statement and the approach seems kind of obvious: Detect the staff-lines, remove them, do some template matching to detect smaller symbols and finally restore the information that is required to play it back. But the bitter truth is: It is not that easy. There are many subtleties that make a huge difference when using the system on a real dataset. Take a look at these notes, and tell me how the templates should look like:
Well, these symbols look fairly normal, although they are handwritten. I guess by adding some templates, I will catch them. But what to do when they are put in context or look a little different?
You will need a lot of templates. So, some researchers try to find the staff-lines and then remove them, which is the first step where I disagree with most researchers: Why discard information, that guides our reading and is required to make sense of the actual notes? I claim, that removing the staff-lines is not required, if the right approach is used.
But what is the right approach, though?
My hopes lie in a new technology, called Deep Learning. Check it out, if you have never hear about it before. Basically it’s a really clever way of doing machine learning, where you can perform supervised learning very easily – you more or less just provide the data and the expected output – and let the machine figure out the rest by itself. In practice, it’s a little bit more challenging, but you get the idea.
So far, I had great success with classifying handwritten music symbols and entire images of music scores. Check this out:
But to be honest, you need some fantasy to guess the right classes of music symbols here (they are Sixteenth-Rest, 2-4-Time, Sixteenth-Note, Cut-Time, Quarter-Rest and Sixteenth-Note).
The next step is to locate music symbols in an entire sheet of music scores. I hope that it will work out as well as the first few experiments.
From now on, I will keep you updated more regularly on my research progress. I promise!
Phil Ferriere and I have been working on this tutorial that explains how to setup Deep Learning libraries on Windows, so they give optimal performance.
Hold on a second… you just created a new website with Concrete 5 a few months ago, right? True! It was on my-it.at. So why another website?
I came to the conclusion, that setting up a website is actually way more work than it should be. Setting up database, taking care of the web-server, PHP-version and other technical detail is something that I believe should be a matter of the past, especially in the time of Platform-as-a-Service. So I gave WordPress.com a shot and decided to move all my websites to WordPress. The price is similar, I don’t have to worry about maintenance, the editing interface is quite comparable and the pricing is actually the same.
I also recommended this kind of website to my friend Lucio Golino, and soon he will have his own website as well.
For quite a while, I am working on improving how we develop mobile applications. I’ve bundled my findings and experiences in a talk that I gave at the Software Quality Days 2017 in Vienna.
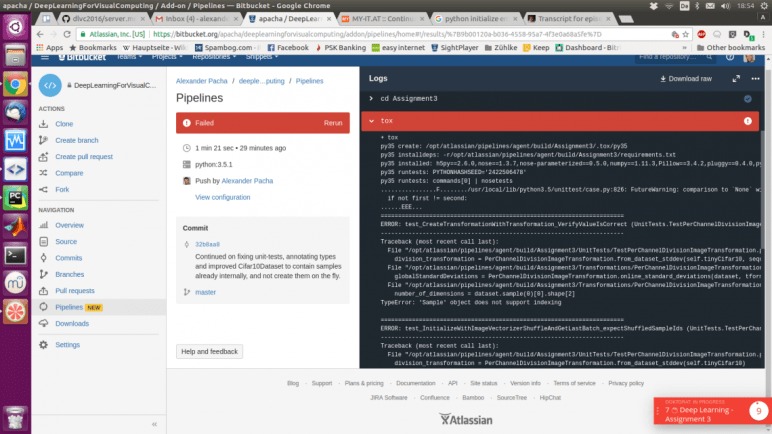
The great article about Bitrise Pipelines and Tox for Python CI unfortunately does no longer exist. But I found this great article.
Basically you need a simple script like this, called bitbucket-pipelines.yml in your repo.
# This is a sample build configuration for Python.# Check our guides at https://confluence.atlassian.com/x/VYk8Lw for more examples.# Only use spaces to indent your .yml configuration.# -----# You can specify a custom docker image from Docker Hub as your build environment.image:python:3.5.1pipelines:default:-step:script:# Modify the commands below to build your repository.-pip install -U tox-pip --version-tox --version# Actually run tox (build, setup and run tests, as specified in tox.ini)-tox
The rest of the setup is quite straight-forward if you are used to work with tox.
I’ve create a file called tox.ini that makes sure that the requirements are installed and the tests are run with nosetests: