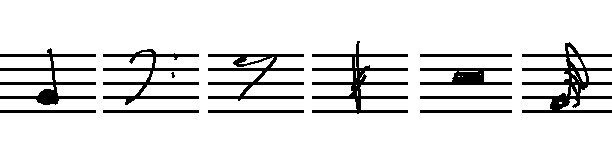I’m regularly receiving e-mail from people all around the world that discovered the fascinating research field of Optical Music Recognition (OMR), the field that studies how to computationally read music notation in documents. I’ve decided to collect some answers here about questions that I usually get asked to provide you with a smoother journey into this field.
What is Optical Music Recognition?
This scientific article gives a thorough introduction, but frankly speaking, I understand if you don’t want to read 30 pages, so here’s the gist: With Optical Music Recognition we try to build computer programs that can make some sense out of notated music (typically printed on paper) like this, ideally enough to allow us to do nice things with it:

For example, play it back to us, that we get a feeling of how the music sounds like.
Or maybe even give us the entire music in a format that allows us to edit it in a music score editor like MuseScore.
Depending on what we want to achieve, the computer needs to comprehend more or less:

If we just want to understand whether there is some music in an image or not, we don’t need very complicated methods. But if we want to reconstruct everything we need to find and understand everything that appears in an image. While the ultimate goal would be to build a system that can obtain the structured encoding (e.g., a MusicXML file), you can already enable many useful application with a simpler system.
How does Optical Music Recognition relate to other fields and how is it different from Optical Character Recognition?
OMR overlaps with several other fields, and heavily relies on computer vision methods to visually understand the content of an image:

However, OMR is expected to not just visually understand the contents of an image, but also restore the underlying music (at least to a certain degree). Simply put: It’s not enough to just find the dots and lines in this image, but we also have to understand what they mean and that depending on where dots appears, they mean something completely different:

Music notation is a featural writing system, which makes it different from written text. A black dot in music notation means nothing on it’s own. Only the configuration—how they are placed in relation to other objects—give it meaning. What the exact meaning is, is defined by the syntactic and semantic rules of music notation.
Why is Optical Music Recognition hard?
There are a couple of reasons, why OMR is considered a very hard challenge and until this day is subject to ongoing research.
Visual Recognition
For beautifully written and typeset music sheets, this seems to be an easy task with modern computers, but when it comes to handwritten music, even humans sometimes struggle to make some sense out of the music:

Errors propagate
Tiny errors can have catastrophic consequences: Consider this small snippet of Debussy’s Clair de Lune:

If we just miss two tiny accidentals at the beginning, the result is completely different:

Such small errors can be the results of image degradations and while the computer managed to correctly recognize 99% of all symbols, the result can still be so bad, that musicians are unwilling to accept the result, because they rely on the correctness of the score to perform a piece of music.
Correcting errors is non-trivial
The support for correcting errors in common music notation editors is not great, because they were not built for it. Say, if I want to fix the error from above by changing the key signature again, MuseScore will automatically generate a couple of accidentals to keep the pitch of all notes the same. So we fixed one problem, but introduced many others:

The rules of music notation are sometimes bent (or even broken)
Musicians are expected to not only be able to read music scores, but also have a profound understanding of the rules that govern it. It’s a process that can take years, and even then you will still encounter situations that will make you wonder, what the intention of the composer was. One common example of violated rules of music notation is the meter in music that has many triplets:

This visualization includes all triplets, but the small 3 on top of the eighth notes are commonly omitted, starting with the second bar. If you were to be a computer that strictly interprets the durations of the notes as they appear, this would cause problems, because you now have 9 eighth notes in a measure where you only expect 6, which violates the meter of the measure.
In some extreme examples, ambiguities and violations of the rules of music notation leave us no choice but to evaluate different hypotheses and pick the most likely one.

How does Optical Music Recognition work?
Over the past 50 years, many researchers attempted to build systems that are capable of reconstructing music from images. Most approaches use a pipeline to process images, similar to this one:
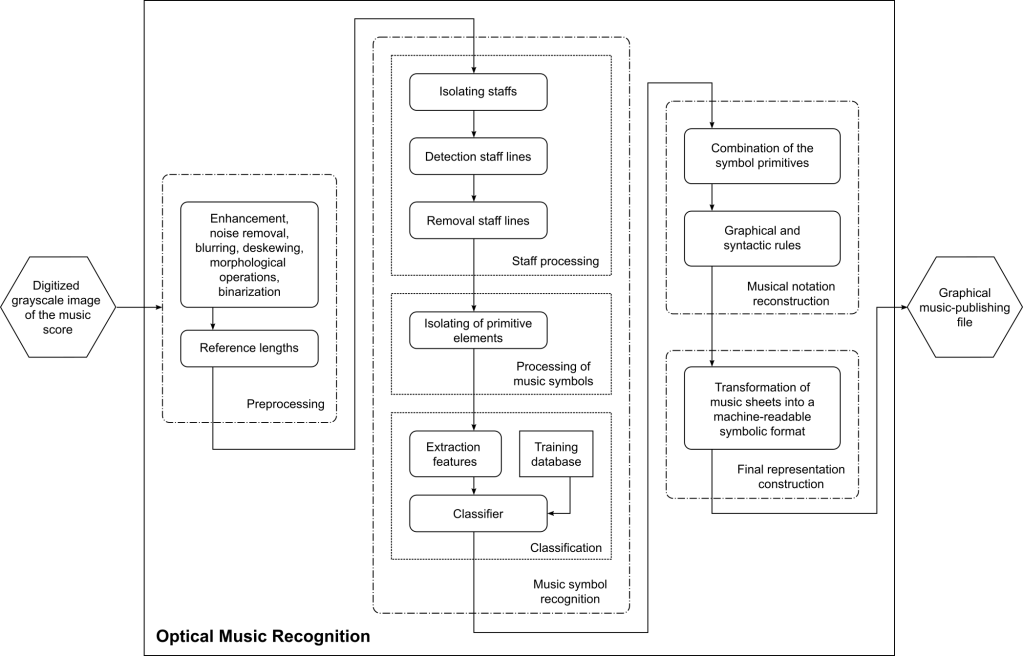
With the advent of Deep Learning, some steps have been merged, removed, or added, but most approaches still build upon the idea to perform one step after another, trying to recover more and more information as they move along.
The most notable exception to this rule are so-called end-to-end systems, that try to use a machine-learning approach that performs all these steps in a single neural network. While such approaches are still limited, they are an appealing alternative to explore in the future.
I want to build an Optical Music Recognition system myself – how do I start?
Depending on where you come from, I recommend you to familiarize yourself with the following things:
- Music notation: Especially if you are an engineer, you might not be familiar with all of the intricacies of music notation and underestimate the complexity. Seeing simple examples is quite different from experiencing more interesting music notation in the wild. A system that only works for a small toy example is simply not sufficient. Not even for Mozart.
- Deep Learning: Machine learning, especially deep learning, has fueled most of the advances the field made in the last 5-10 years. If you have no knowledge about deep learning, you’re in luck, because I’m teaching it at the TU Wien and you can watch all of my lectures on YouTube. If you prefer to read instead, there are also plenty of textbooks available.
- Terminology of the field: If you are really serious about your research, you need to familiarize yourself with the terminology, taxonomy, and goals. Now would be a good time to do read this scientific article.
- Define your own goals: Once you understand OMR to a certain degree, think about your own goals. What do you want to achieve with it? What is the problem you’re trying to solve? Why is it a problem? What would be your solution and why is it a solution? Which resources do you have? Don’t underestimate the complexity of this field. Having a few months for a master thesis will allow you to tackle one small (sub-)problem, but will not allow you to build an entire OMR system from scratch.
- State-of-the-art and open questions: Once you go into research, you need to be aware of what is going on in the field. Hundreds of scientific articles have been published so far. Most of them are listed in the OMR Research Bibliography. Study the recently published articles, attend workshops and conferences and connect with fellow researchers. Maybe you can collaborate with someone, who is interested in doing the same thing.
If you have completed the steps from above and still have questions, feel free to contact me. Good luck with your research!