
In my last post on optical music recognition, my computer was an infant. It was merely able to utter words if presented with an isolated image of a single object. It could distinguish a quarter rest from a g-clef, similar to a baby that can distinguish an apple from a banana. Nothing more. But, it learnt all that by itself (!), only given a couple of thousand annotated examples and a powerful PC.
In this post, I am proud to announce, that my machine has grown up and is now a toddler. It still can’t run or talk. But it can crawl around and find all apples and bananas in the room. It is now capable of detecting music symbols in the music scores like this:

It’s hard to see anything, right? Well, that’s because there are a lot of things going on in music scores. But let’s take it step by step.
If you haven’t read my previous post or following my research, here is the TL;DR: I am teaching my computer to read music scores to do such cool stuff as listening to scores, after taking a picture of them with your smartphone. But while the idea is not new at all, I am following a radically new approach and instead of telling (programming) the computer what to do (first look for lines, then for round objects, then combine them, …), I am letting the computer figure that out by itself. The whole thing is a five-step process, described here, of which I am currently working on step number three: detecting music objects.
We are using deep learning techniques, where a big (convolutional) neural network (think of it as something, that tries to imitate how the brain works) is being shown thousands of images like the following one, along with the information, what is in there and watch what happens over time:
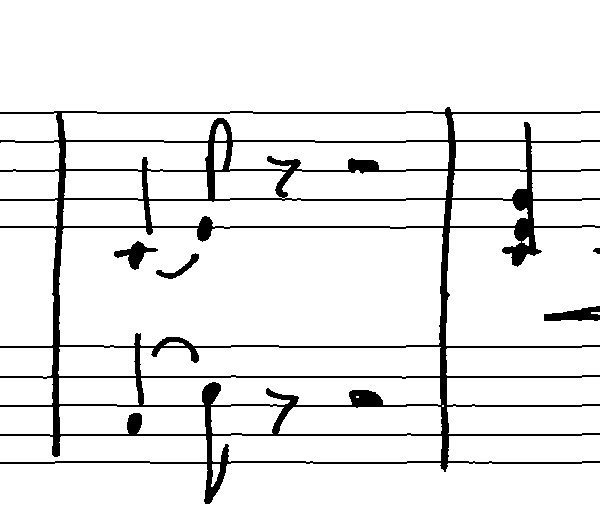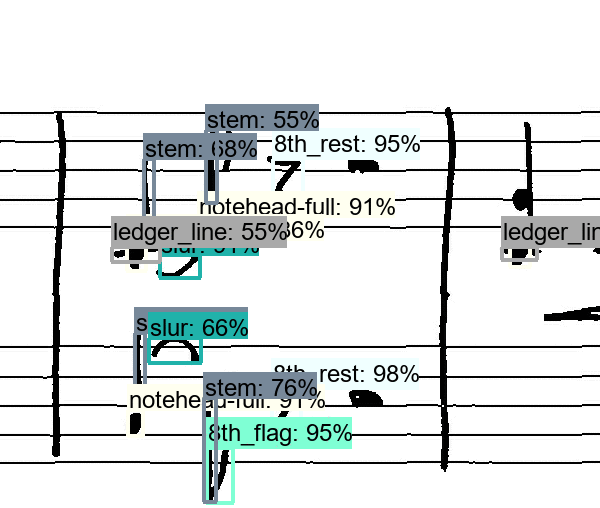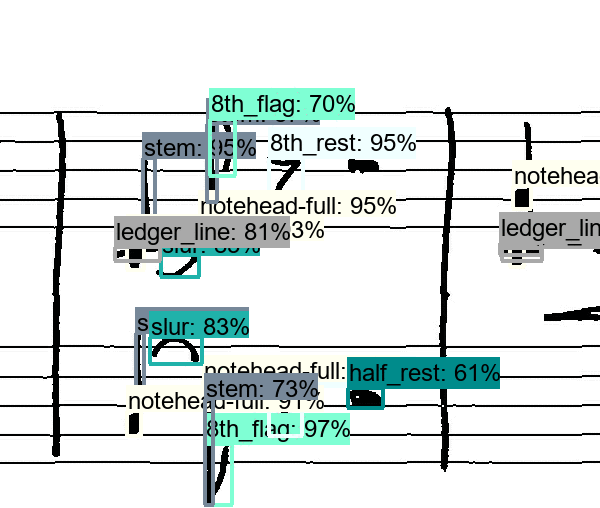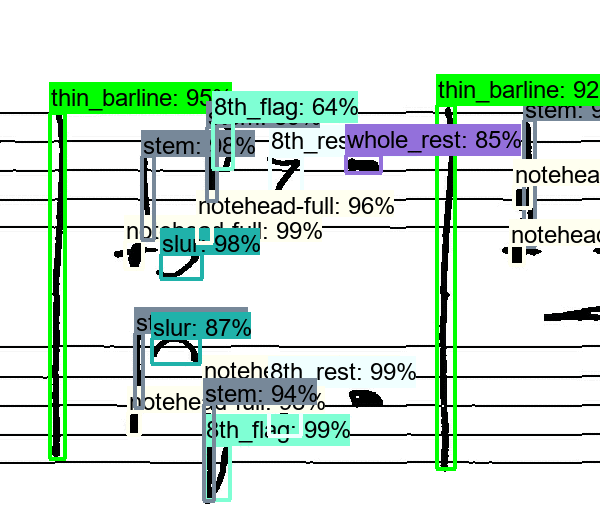
While it starts with only a limited number of simple symbols, that are being detected, it quickly figures out how to detect all sorts of symbols. And while it is clearly not perfect, e.g. the half rest is confused with a whole rest in the above stave, it is remarkable, what the network was capable of learning by itself. If you are interested in the technical details, they are described in a scientific paper, that I will present at this year’s International Workshop on Document Analysis Systems in Vienna. But to summarize it: The computer scans the image along a grid with predefined “boxes” and evaluates each box, on whether it contains something of interest or not, called “objectness score”. Once, it found all (or most) potential boxes, it starts to refine them and assign a label to each box, e.g. “I think that is a G-clef in the left upper corner at position X, Y”. This process is end-to-end trainable with the so-called Faster R-CNN approach and was implemented with Tensorflow’s Object Detection API.
Did you notice, that the scores here were handwritten? That’s right. We are working on the CVC-MUSCIMA dataset that contains 1000 handwritten music scores, which was annotated in the MUSCIMA++ dataset by my outstanding colleague Jan Hajič, whose effort I am very grateful for.
And while this looks nice already, it has one significant drawback: The images you see above are not the entire score. What happens to a symbol that is bigger than image section? Well, it is not detected at the moment. But I wouldn’t mention it here if that was the end of the line. In fact, I’ve been working on detecting symbols in the full image already, and the first results are very promising:

It still has a couple of other issues, for example some very small objects, that were not properly detected or some confusions, but it is already a big step towards making this work in such a way, that the computer will be able to improve over time, by simply providing more data.
I will continue to work on the object detection a little longer before I start teaching the computer, what those symbols actually mean. Once I taught him how to find the symbols, how they relate to each other and what they mean, I hope it will grow up and sing beautiful songs to me. Until then, I will have to sing them by myself. 🙂
Update 27.04.2018: If you are interested, here is my presentation on this subject, that I gave at the DAS 2018.

Thank you for publishing this work, it is a very interesting material indeed. Did you consider using other object detection algorithms, such as the quite famous yolo?
LikeLike
Thanks for the Feedback. Yes, we did consider YOLO (which already is in Version 3), but were hoping that it finally get’s implemented into the Tensorflow Object Detection API, that we use already (https://github.com/tensorflow/models/issues/2267) which would make it easier as we wouldn’t have to setup a new tool chain. We’re also considering RetinaNet in upcoming experiments: https://github.com/fizyr/keras-retinanet
LikeLike